









Configuration File Variable Reference
This reference lists all the variables that you can specify to provide cluster configuration options to the Tanzu CLI.
To set these variables in a YAML configuration file, leave a space between the colon (:) and the variable value. For example:
CLUSTER_NAME: my-cluster
Line order in the configuration file does not matter. Options are presented here in alphabetical order. Also, see the Configuration Value Precedence section below.
Common Variables for All Target Platforms
This section lists variables that are common to all target platforms. These variables may apply to management clusters, workload clusters, or both. For more information, see Configure Basic Management Cluster Creation Information in Create a Management Cluster Configuration File.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
APISERVER_EVENT_RATE_LIMIT_CONF_BASE64 |
✔ | ✔ | Class-based clusters only. Enables and configures an EventRateLimit admission controller to moderate traffic to the Kubernetes API server. Set this property by creating an EventRateLimit configuration file config.yaml as described in the Kubernetes documentation and then converting it into a string value by running base64 -w 0 config.yaml |
CAPBK_BOOTSTRAP_TOKEN_TTL |
✔ | ✖ | Optional; defaults to 15m, 15 minutes. The TTL value of the bootstrap token used by kubeadm during cluster init operations. |
CLUSTER_API_SERVER_PORT |
✔ | ✔ | Optional; defaults to 6443. This variable is ignored if you enable NSX Advanced Load Balancer (vSphere); to override the default Kubernetes API server port for deployments with NSX Advanced Load Balancer, set VSPHERE_CONTROL_PLANE_ENDPOINT_PORT. |
CLUSTER_CIDR |
✔ | ✔ | Optional; defaults to 100.96.0.0/11. The CIDR range to use for pods. Change the default value only if the default range is unavailable. |
CLUSTER_NAME |
✔ | ✔ | This name must comply with DNS hostname requirements as outlined in RFC 952 and amended in RFC 1123, and must be 42 characters or less. For workload clusters, this setting is overridden by the CLUSTER_NAME argument passed to tanzu cluster create.For management clusters, if you do not specify CLUSTER_NAME, a unique name is generated. |
CLUSTER_PLAN |
✔ | ✔ | Required. Set to dev, prod, or a custom plan as exemplified in New Plan nginx.The dev plan deploys a cluster with a single control plane node. The prod plan deploys a highly available cluster with three control plane nodes. |
CNI |
✖ | ✔ | Optional; defaults to antrea. Container network interface. Do not override the default value for management clusters. For workload clusters, you can set CNI to antrea, calico, or none. The calico option is not supported on Windows. For more information, see Deploy a Cluster with a Non-Default CNI. To customize your Antrea configuration, see Antrea CNI Configuration below. |
CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED |
✔ | ✔ | Optional; defaults to true. Set to false if you want control plane node VM certificates not to auto-renew before they expire. For more information, see Control Plane Node Certificate Auto-Renewal. |
CONTROLPLANE_CERTIFICATE_ROTATION_DAYS_BEFORE |
✔ | ✔ | Optional; defaults to 90. If CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED is true, set to the number of days before the certificate expiration date to automatically renew cluster node certificates. For more information, see Control Plane Node Certificate Auto-Renewal. |
ENABLE_AUDIT_LOGGING |
✔ | ✔ | Optional; defaults to false. Audit logging for the Kubernetes API server. To enable audit logging, set to true. Tanzu Kubernetes Grid writes these logs to /var/log/kubernetes/audit.log. For more information, see Audit Logging.Enabling Kubernetes auditing can result in very high log volumes. To handle this quantity, VMware recommends using a log forwarder such as Fluent Bit. |
ENABLE_AUTOSCALER |
✖ | ✔ | Optional; defaults to false. If set to true, you must set additional variables in the Cluster Autoscaler table below. |
ENABLE_CEIP_PARTICIPATION |
✔ | ✖ | Optional; defaults to true. Set to false to opt out of the VMware Customer Experience Improvement Program. You can also opt in or out of the program after deploying the management cluster. For information, see Opt In or Out of the VMware CEIP in Manage Participation in CEIP and Customer Experience Improvement Program (“CEIP”). |
ENABLE_DEFAULT_STORAGE_CLASS |
✖ | ✔ | Optional; defaults to true. For information about storage classes, see Dynamic Storage. |
ENABLE_MHC etc. |
✔ | ✔ | Optional; see Machine Health Checks below for the full set of MHC variables and how they work. |
IDENTITY_MANAGEMENT_TYPE |
✔ | ✖ | Optional; defaults to none. For management clusters: Set |
INFRASTRUCTURE_PROVIDER |
✔ | ✔ | Required. Set to vsphere or tkg-service-vsphere. |
NAMESPACE |
✖ | ✔ | Optional; defaults to default, to deploy workload clusters to a namespace named default. |
SERVICE_CIDR |
✔ | ✔ | Optional; defaults to to 100.64.0.0/13. The CIDR range to use for the Kubernetes services. Change this value only if the default range is unavailable. |
Identity Providers - OIDC
If you set IDENTITY_MANAGEMENT_TYPE: oidc, set the following variables to configure an OIDC identity provider. For more information, see Configure Identity Management in Create a Management Cluster Configuration File.
Tanzu Kubernetes Grid integrates with OIDC using Pinniped, as described in About Identity and Access Management.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
CERT_DURATION |
✔ | ✖ | Optional; defaults to 2160h. Set this variable if you configure Pinniped to use self-signed certificates managed by cert-manager. |
CERT_RENEW_BEFORE |
✔ | ✖ | Optional; defaults to 360h. Set this variable if you configure Pinniped to use self-signed certificates managed by cert-manager. |
OIDC_IDENTITY_PROVIDER_CLIENT_ID |
✔ | ✖ | Required. The client_id value that you obtain from your OIDC provider. For example, if your provider is Okta, log in to Okta, create a Web application, and select the Client Credentials options in order to get a client_id and secret. This setting will be stored in a secret that will be referenced by OIDCIdentityProvider.spec.client.secretName in the Pinniped OIDCIdentityProvider custom resource. |
OIDC_IDENTITY_PROVIDER_CLIENT_SECRET |
✔ | ✖ | Required. The secret value that you obtain from your OIDC provider. Do not base64-encode this value. |
OIDC_IDENTITY_PROVIDER_GROUPS_CLAIM |
✔ | ✖ | Optional. The name of your groups claim. This is used to set a user’s group in the JSON Web Token (JWT) claim. The default value is groups. This setting corresponds to OIDCIdentityProvider.spec.claims.groups in the Pinniped OIDCIdentityProvider custom resource. |
OIDC_IDENTITY_PROVIDER_ISSUER_URL |
✔ | ✖ | Required. The IP or DNS address of your OIDC server. This setting corresponds to OIDCIdentityProvider.spec.issuer in the Pinniped custom resource. |
OIDC_IDENTITY_PROVIDER_SCOPES |
✔ | ✖ | Required. A comma separated list of additional scopes to request in the token response. For example, "email,offline_access". This setting corresponds to OIDCIdentityProvider.spec.authorizationConfig.additionalScopes in the Pinniped OIDCIdentityProvider custom resource. |
OIDC_IDENTITY_PROVIDER_USERNAME_CLAIM |
✔ | ✖ | Required. The name of your username claim. This is used to set a user’s username in the JWT claim. Depending on your provider, enter claims such as user_name, email, or code. This setting corresponds to OIDCIdentityProvider.spec.claims.username in the Pinniped OIDCIdentityProvider custom resource. |
OIDC_IDENTITY_PROVIDER_ADDITIONAL_AUTHORIZE_PARAMS |
✔ | ✖ | Optional. Add custom parameters to send to the OIDC identity provider. Depending on your provider, these claims may be required to receive a refresh token from the provider. For example, prompt=consent. Separate multiple values with commas. This setting corresponds to OIDCIdentityProvider.spec.authorizationConfig.additionalAuthorizeParameters in the Pinniped OIDCIdentityProvider custom resource. |
OIDC_IDENTITY_PROVIDER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Optional. A Base64-encoded CA bundle to establish TLS with OIDC identity providers. This setting corresponds to OIDCIdentityProvider.spec.tls.certificateAuthorityData in the Pinniped OIDCIdentityProvider custom resource. |
SUPERVISOR_ISSUER_URL |
✔ | ✖ | Do not modify. This variable is automatically updated in the configuration file when you run the tanzu cluster create command command. This setting corresponds to JWTAuthenticator.spec.audience in the Pinniped JWTAuthenticator custom resource and FederationDomain.spec.issuer in the Pinniped FederationDomain custom resource. |
SUPERVISOR_ISSUER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Do not modify. This variable is automatically updated in the configuration file when you run the tanzu cluster create command command. This setting corresponds to JWTAuthenticator.spec.tls.certificateAuthorityData in the Pinniped JWTAuthenticator custom resource. |
Identity Providers - LDAP
If you set IDENTITY_MANAGEMENT_TYPE: ldap, set the following variables to configure an LDAP identity provider. For more information, see Configure Identity Management in Create a Management Cluster Configuration File.
Tanzu Kubernetes Grid integrates with LDAP using Pinniped, as described in About Identity and Access Management. Each of the variables below corresponds to a configuration setting in the Pinniped LDAPIdentityProvider custom resource. For a full description of these settings and information on how to configure them, see LDAPIdentityProvider in the Pinniped documentation.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
| For connection to the LDAP server: | |||
LDAP_HOST |
✔ | ✖ | Required. The IP or DNS address of your LDAP server. If the LDAP server is listening on the default port 636, which is the secured configuration, you do not need to specify the port. If the LDAP server is listening on a different port, provide the address and port of the LDAP server, in the form “host:port”. This setting corresponds to LDAPIdentityProvider.spec.host in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_ROOT_CA_DATA_B64 |
✔ | ✖ | Optional. If you are using an LDAPS endpoint, paste the Base64-encoded contents of the LDAP server certificate. This setting corresponds to LDAPIdentityProvider.spec.tls.certificateAuthorityData in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_BIND_DN |
✔ | ✖ | Required. The DN for an existing application service account. For example, “cn=bind-user,ou=people,dc=example,dc=com”. The connector uses these credentials to search for users and groups. This service account must have at least read-only permissions to perform the queries configured by the other LDAP_* configuration options. Included in the secret for spec.bind.secretName in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_BIND_PASSWORD |
✔ | ✖ | Required. The password for the application service account set in LDAP_BIND_DN. Included in the secret for spec.bind.secretName in the Pinniped LDAPIdentityProvider custom resource. |
| For user search: | |||
LDAP_USER_SEARCH_BASE_DN |
✔ | ✖ | Required. The point from which to start the LDAP search. For example, OU=Users,OU=domain,DC=io. This setting corresponds to LDAPIdentityProvider.spec.userSearch.base in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_USER_SEARCH_FILTER |
✔ | ✖ | Optional. An optional filter to be used by the LDAP search. This setting corresponds to LDAPIdentityProvider.spec.userSearch.filter in the Pinniped LDAPIdentityProvider custom resource. Starting in TKG v2.3, when creating a management cluster or updating the Pinniped package secret for an existing management cluster, you must use the Pinniped format for this value. For example, &(objectClass=posixAccount)(uid={}). |
LDAP_USER_SEARCH_ID_ATTRIBUTE |
✔ | ✖ | Optional. The LDAP attribute that contains the user ID. Defaults to dn. This setting corresponds to LDAPIdentityProvider.spec.userSearch.attributes.uid in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_USER_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Required. The LDAP attribute that holds the username of the user. For example, mail. This setting corresponds to LDAPIdentityProvider.spec.userSearch.attributes.username in the Pinniped LDAPIdentityProvider custom resource. |
| For group search: | |||
LDAP_GROUP_SEARCH_BASE_DN |
✔ | ✖ | Optional. The point from which to start the LDAP search. For example, OU=Groups,OU=domain,DC=io. When not set, group search is skipped. This setting corresponds to LDAPIdentityProvider.spec.groupSearch.base in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_GROUP_SEARCH_FILTER |
✔ | ✖ | Optional. An optional filter to be used by the LDAP search. This setting corresponds to LDAPIdentityProvider.spec.groupSearch.filer in the Pinniped LDAPIdentityProvider custom resource. Starting in TKG v2.3, when creating a management cluster or updating the Pinniped package secret for an existing management cluster, you must use the Pinniped format for this value. For example, &(objectClass=posixGroup)(memberUid={}). |
LDAP_GROUP_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Optional. The LDAP attribute that holds the name of the group. Defaults to dn. This setting corresponds to LDAPIdentityProvider.spec.groupSearch.attributes.groupName in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_GROUP_SEARCH_USER_ATTRIBUTE |
✔ | ✖ | Optional. The attribute of the user record to use as the value of the membership attribute of the group record. Defaults to dn. This setting corresponds to LDAPIdentityProvider.spec.groupSearch.userAttributeForFilter in the Pinniped LDAPIdentityProvider custom resource. |
LDAP_GROUP_SEARCH_SKIP_ON_REFRESH |
✔ | ✖ | Optional. Defaults to false. When set to true, a user’s group memberships are updated only at the beginning of the user’s daily session. Setting LDAP_GROUP_SEARCH_SKIP_ON_REFRESH to true is not recommended and should be done only when it is otherwise impossible to make the group query fast enough to run during session refreshes. This setting corresponds to LDAPIdentityProvider.spec.groupSearch.skipGroupRefresh in the Pinniped LDAPIdentityProvidercustom resource. |
Node Configuration
Configure the control plane and worker nodes, and the operating system that the node instances run. For more information, see Configure Node Settings in Create a Management Cluster Configuration File.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
CONTROL_PLANE_MACHINE_COUNT |
✔ | ✔ | Optional. Deploy a workload cluster with more control plane nodes than the dev and prod plans define by default. The number of control plane nodes that you specify must be odd. |
CONTROL_PLANE_NODE_LABELS |
✔ | ✔ | Class-based clusters only. Assign custom persistent labels to the control plane nodes, for example CONTROL_PLANE_NODE_LABELS: ‘key1=value1,key2=value2’. To configure this in a legacy, plan-based cluster, use a ytt overlay as described in Custom Node Labels.Worker node labels are set in their node pool as described in Manage Node Pools of Different VM Types. |
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | This allows the user to specify a comma-delimited list of DNS servers to be configured on control plane nodes, for example, CONTROL_PLANE_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Supported on Ubuntu and Photon; not supported on Windows. For an example use case, see Node IPAM below. |
CONTROL_PLANE_NODE_SEARCH_DOMAINS |
✔ | ✔ | Class-based clusters only. Configures the .local search domains for cluster nodes, for example CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. To configure this in a legacy, plan-based cluster on vSphere, use a ytt overlay as described in Resolve .local Domain. |
CONTROLPLANE_SIZE |
✔ | ✔ | Optional. Size for control plane node VMs. Overrides the SIZE and VSPHERE_CONTROL_PLANE_ parameters. See SIZE for possible values. |
OS_ARCH |
✔ | ✔ | Optional. Architecture for node VM OS. Default and only current choice is amd64. |
OS_NAME |
✔ | ✔ | Optional. Node VM OS. Defaults to ubuntu for Ubuntu LTS. Can also be photon for Photon OS. |
OS_VERSION |
✔ | ✔ | Optional. Version for OS_NAME OS, above. Defaults to 22.04 for Ubuntu. Can be 20.04for Ubuntu, or 5 or 3 for Photon. |
SIZE |
✔ | ✔ | Optional. Size for both control plane and worker node VMs. Overrides the VSPHERE_CONTROL_PLANE_* and VSPHERE_WORKER_* parameters. Set small, medium, large, or extra-large as described in Predefined Node Sizes. |
WORKER_MACHINE_COUNT |
✔ | ✔ | Optional. Deploy a workload cluster with more worker nodes than the dev and prod plans define by default. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | This allows the user to specify a comma-delimited list of DNS servers to be configured on worker nodes, for example, WORKER_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Supported on Ubuntu and Photon; not supported on Windows. For an example use case, see Node IPAM below. |
WORKER_NODE_SEARCH_DOMAINS |
✔ | ✔ | Class-based clusters only. Configures the .local search domains for cluster nodes, for example CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. To configure this in a legacy, plan-based cluster on vSphere, use a ytt overlay as described in Resolve .local Domain. |
WORKER_SIZE |
✔ | ✔ | Optional. Size for worker node VMs. Overrides the SIZE and VSPHERE_WORKER_ parameters. See SIZE for possible values. |
CUSTOM_TDNF_REPOSITORY_CERTIFICATE |
✔ | ✔ | (Technical Preview) Optional. Set if you use a customized tdnf repository server with a self-signed certificate, rather than the photon default tdnf repository server. Enter the contents of the base64 encoded certificate of tdnf repository server. It deletes all repos under |
Pod Security Standards for Pod Security Admission Controller
Configure Pod Security Standards for a cluster-wide Pod Security Admission (PSA) controller. the control plane and worker nodes, and the operating system that the node instances run. For more information, see Pod Security Admission Controller.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
POD_SECURITY_STANDARD_AUDIT |
✖ | ✔ | Optional, defaults to restricted. Sets security policy for the audit mode of cluster-wide PSA controller. Possible values: restricted, baseline, and privileged. |
POD_SECURITY_STANDARD_DEACTIVATED |
✖ | ✔ | Optional, defaults to false. Set to true to deactivate cluster-wide PSA. |
POD_SECURITY_STANDARD_ENFORCE |
✖ | ✔ | Optional, defaults to no value. Sets security policy for the enforce mode of cluster-wide PSA controller. Possible values: restricted, baseline, and privileged. |
POD_SECURITY_STANDARD_WARN |
✖ | ✔ | Optional, defaults to restricted. Sets security policy for the warn mode of cluster-wide PSA controller. Possible values: restricted, baseline, and privileged. |
Kubernetes and Package Tuning (Class-based clusters only)
Kubernetes API servers, Kubelets, kapp-controller, and other components expose various configuration flags for tuning, for example the --tls-cipher-suites flag to configure cipher suites for security hardening, the --election-timeout flag to increase etcd timeout in a large cluster etc.
ImportantThese Kubernetes configuration variables are for advanced users. VMware does not guarantee the functionality of clusters configured with arbitrary combinations of these settings.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
APISERVER_EXTRA_ARGS |
✔ | ✔ | Specify kube-apiserver flags in the format “key1=value1;key2=value2”. For example, set cipher suites with APISERVER_EXTRA_ARGS: “tls-min-version=VersionTLS12;tls-cipher-suites=TLS_RSA_WITH_AES_256_GCM_SHA384” |
CONTROLPLANE_KUBELET_EXTRA_ARGS |
✔ | ✔ | Specify control plane kubelet flags in the format “key1=value1;key2=value2”. For example, limit the number of control plane pods with CONTROLPLANE_KUBELET_EXTRA_ARGS: “max-pods=50” |
ETCD_EXTRA_ARGS |
✔ | ✔ | Specify etcd flags in the format “key1=value1;key2=value2”. For example, if the cluster has more than 500 nodes or the storage has bad performance, you can increase heartbeat-interval and election-timeout with ETCD_EXTRA_ARGS: “heartbeat-interval=300;election-timeout=2000” |
KAPP_CONCURRENCY |
✔ | ✔ | Sets the number of kapp-controller pods that stay running at any time during a kapp-controller version update. Default: 10 |
KAPP_ROLLINGUPDATE_MAXSURGE |
✔ | ✔ | When KAPP_UPDATE_STRATEGY is set to RollingUpdate, specifies the maximum number of additional kapp-controller pods that can be temporarily created over the usual desired number of pods during kapp-controller update, based on Kubernetes deployment strategy. Defaults to 1. |
KAPP_ROLLINGUPDATE_MAXUNAVAILABLE |
✔ | ✔ | When KAPP_UPDATE_STRATEGY is set to RollingUpdate, specifies the maximum number of kapp-controller pods that can be unavailable during kapp-controller update, based on Kubernetes deployment strategy. Defaults to 0. |
KAPP_UPDATE_STRATEGY |
✔ | ✔ | Specify how kapp-controller pods maintain component continuity during kapp-controller update, based on Kubernetes deployment strategy options. Possible values are RollingUpdate and Recreate. Defaults to RollingUpdate. |
KUBE_CONTROLLER_MANAGER_EXTRA_ARGS |
✔ | ✔ | Specify kube-controller-manager flags in the format “key1=value1;key2=value2”. For example, turn off performance profiling with KUBE_CONTROLLER_MANAGER_EXTRA_ARGS: “profiling=false” |
KUBE_SCHEDULER_EXTRA_ARGS |
✔ | ✔ | Specify kube-scheduler flags in the format “key1=value1;key2=value2”. For example, enable Single Pod Access Mode with KUBE_SCHEDULER_EXTRA_ARGS: “feature-gates=ReadWriteOncePod=true” |
WORKER_KUBELET_EXTRA_ARGS |
✔ | ✔ | Specify worker kubelet flags in the format “key1=value1;key2=value2”. For example, limit the number of worker pods with WORKER_KUBELET_EXTRA_ARGS: “max-pods=50” |
Cluster Autoscaler
The following additional variables are available to configure if ENABLE_AUTOSCALER is set to true. For information about Cluster Autoscaler, see Scale Workload Clusters.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
AUTOSCALER_MAX_NODES_TOTAL |
✖ | ✔ | Optional; defaults to 0. Maximum total number of nodes in the cluster, worker plus control plane. Sets the value for the Cluster Autoscaler parameter max-nodes-total. Cluster Autoscaler does not attempt to scale your cluster beyond this limit. If set to 0, Cluster Autoscaler makes scaling decisions based on the minimum and maximum SIZE settings that you configure. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD |
✖ | ✔ | Optional; defaults to 10m. Sets the value for the Cluster Autoscaler parameter scale-down-delay-after-add. Amount of time that Cluster Autoscaler waits after a scale-up operation and then resumes scale-down scans. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE |
✖ | ✔ | Optional; defaults to 10s. Sets the value for the Cluster Autoscaler parameter scale-down-delay-after-delete. Amount of time that Cluster Autoscaler waits after deleting a node and then resumes scale-down scans. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE |
✖ | ✔ | Optional; defaults to 3m. Sets the value for the Cluster Autoscaler parameter scale-down-delay-after-failure. Amount of time that Cluster Autoscaler waits after a scale-down failure and then resumes scale-down scans. |
AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME |
✖ | ✔ | Optional; defaults to 10m. Sets the value for the Cluster Autoscaler parameter scale-down-unneeded-time. Amount of time that Cluster Autoscaler must wait before scaling down an eligible node. |
AUTOSCALER_MAX_NODE_PROVISION_TIME |
✖ | ✔ | Optional; defaults to 15m. Sets the value for the Cluster Autoscaler parameter max-node-provision-time. Maximum amount of time Cluster Autoscaler waits for a node to be provisioned. |
AUTOSCALER_MIN_SIZE_0 |
✖ | ✔ | Required. Minimum number of worker nodes. Cluster Autoscaler does not attempt to scale down the nodes below this limit. If not set, defaults to the value of WORKER_MACHINE_COUNT for clusters with a single worker node or WORKER_MACHINE_COUNT_0 for clusters with multiple worker nodes. |
AUTOSCALER_MAX_SIZE_0 |
✖ | ✔ | Required. Maximum number of worker nodes. Cluster Autoscaler does not attempt to scale up the nodes beyond this limit. If not set, defaults to the value of WORKER_MACHINE_COUNT for clusters with a single worker node or WORKER_MACHINE_COUNT_0 for clusters with multiple worker nodes. |
Proxy Configuration
If your environment is internet-restricted or otherwise includes proxies, you can optionally configure Tanzu Kubernetes Grid to send outgoing HTTP and HTTPS traffic from kubelet, containerd, and the control plane to your proxies.
Tanzu Kubernetes Grid allows you to enable proxies for any of the following:
- For both the management cluster and one or more workload clusters
- For the management cluster only
- For one or more workload clusters
For more information, see Configure Proxies in Create a Management Cluster Configuration File.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
TKG_HTTP_PROXY_ENABLED |
✔ | ✔ | Optional, to send outgoing HTTP(S) traffic from the management cluster to a proxy, for example in an internet-restricted environment, set this to |
TKG_HTTP_PROXY |
✔ | ✔ | Optional, set if you want to configure a proxy; to deactivate your proxy configuration for an individual cluster, set this to
For example, |
TKG_HTTPS_PROXY |
✔ | ✔ | Optional, set if you want to configure a proxy. Only applicable when TKG_HTTP_PROXY_ENABLED = true. The URL of your HTTPS proxy. You can set this variable to the same value as TKG_HTTP_PROXY or provide a different value. The URL must start with http://. If you set TKG_HTTPS_PROXY, you must also set TKG_HTTP_PROXY. |
TKG_NO_PROXY |
✔ | ✔ | Optional. Only applicable when One or more network CIDRs or hostnames that must bypass the HTTP(S) proxy, comma-separated and listed without spaces or wildcard characters ( For example, Do not include: You need not include Include:
Important: In environments where Tanzu Kubernetes Grid runs behind a proxy, |
TKG_PROXY_CA_CERT |
✔ | ✔ | Optional. Set if your proxy server uses a self-signed certificate. Provide the CA certificate in base64 encoded format, for example TKG_PROXY_CA_CERT: “LS0t[…]tLS0tLQ==””. |
TKG_NODE_SYSTEM_WIDE_PROXY |
✔ | ✔ | (Technical Preview) Optional. Puts the following settings into export HTTP_PROXY=$TKG_HTTP_PROXY export HTTPS_PROXY=$TKG_HTTPS_PROXY export NO_PROXY=$TKG_NO_PROXY When users SSH in to the TKG node and run commands, by default, the commands use the defined variables. Systemd processes are not impacted. |
Antrea CNI Configuration
Additonal optional variables to set if CNI is set to antrea. For more information, see Configure Antrea CNI in Create a Management Cluster Configuration File.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
ANTREA_DISABLE_UDP_TUNNEL_OFFLOAD |
✔ | ✔ | Optional; defaults to false. Set to true to deactivate Antrea’s UDP checksum offloading. Setting this variable to true avoids known issues with underlay network and physical NIC network drivers. |
ANTREA_EGRESS |
✔ | ✔ | Optional; defaults to true. Enable this variable to define the SNAT IP that is used for Pod traffic egressing the cluster. For more information, see Egress in the Antrea documentation. |
ANTREA_EGRESS_EXCEPT_CIDRS |
✔ | ✔ | Optional. The CIDR ranges that egresses will not SNAT for outgoing Pod traffic. Include the quotes (““).For example, “10.0.0.0/6”. |
ANTREA_ENABLE_USAGE_REPORTING |
✔ | ✔ | Optional; defaults to false. Activates or deactivates usage reporting (telemetry). |
ANTREA_FLOWEXPORTER |
✔ | ✔ | Optional; defaults to false. Set to true for visibility of network flow. Flow exporter polls the conntrack flows periodically and exports the flows as IPFIX flow records. For more information, see Network Flow Visibility in Antrea in the Antrea documentation. |
ANTREA_FLOWEXPORTER_ACTIVE_TIMEOUT |
✔ | ✔ | Optional; defaults to Note: The valid time units are |
ANTREA_FLOWEXPORTER_COLLECTOR_ADDRESS |
✔ | ✔ | Optional. This variable provides the IPFIX collector address. Include the quotes (““). The default value is “flow-aggregator.flow-aggregator.svc:4739:tls”. For more information, see Network Flow Visibility in Antrea in the Antrea documentation. |
ANTREA_FLOWEXPORTER_IDLE_TIMEOUT |
✔ | ✔ | Optional; defaults to Note: The valid time units are |
ANTREA_FLOWEXPORTER_POLL_INTERVAL |
✔ | ✔ | Optional; defaults to Note: The valid time units are |
ANTREA_IPAM |
✔ | ✔ | Optional; defaults to false. Set to true to allocate IP addresses from IPPools. The desired set of IP ranges, optionally with VLANs, are defined with IPPool CRD. For more information, see Antrea IPAM Capabilities in the Antrea documentation. |
ANTREA_KUBE_APISERVER_OVERRIDE |
✔ | ✔ | Optional, Experimental. Specify the address of the workload cluster’s Kubernetes API server, as CONTROL-PLANE-VIP:PORT. This address should be either maintained by kube-vip or a static IP for a control plane node.Warning: removing kube-proxy and setting ANTREA_KUBE_APISERVER_OVERRIDE so that Antrea alone serves all traffic is Experimental. For more information, see Configure Antrea CNI and Removing kube-proxy in the Antrea documentation. |
ANTREA_MULTICAST |
✔ | ✔ | Optional; defaults to false. Set to true to multicast traffic within the cluster network (between pods), and between the external network and the cluster network. |
ANTREA_MULTICAST_INTERFACES |
✔ | ✔ | Optional. The names of the interface on nodes that are used to forward multicast traffic. Include the quotes (””). For example, “eth0”. |
ANTREA_NETWORKPOLICY_STATS |
✔ | ✔ | Optional; defaults to true. Enable this variable to collect NetworkPolicy statistics. The statistical data includes the total number of sessions, packets, and bytes allowed or denied by a NetworkPolicy. |
ANTREA_NO_SNAT |
✔ | ✔ | Optional; defaults to false. Set to true to deactivate Source Network Address Translation (SNAT). |
ANTREA_NODEPORTLOCAL |
✔ | ✔ | Optional; defaults to true. Set to false to deactivate the NodePortLocal mode. For more information, see NodePortLocal (NPL) in the Antrea documentation. |
ANTREA_NODEPORTLOCAL_ENABLED |
✔ | ✔ | Optional. Set to true to enable NodePortLocal mode, as described in NodePortLocal (NPL) in the Antrea documentation. |
ANTREA_NODEPORTLOCAL_PORTRANGE |
✔ | ✔ | Optional; defaults to 61000-62000. For more information, see NodePortLocal (NPL) in the Antrea documentation. |
ANTREA_POLICY |
✔ | ✔ | Optional; defaults to true. Activates or deactivates the Antrea-native policy API, which are policy CRDs specific to Antrea. Also, the implementation of Kubernetes Network Policies remains active when this variable is enabled. For information about using network policies, see Antrea Network Policy CRDs in the Antrea documentation. |
ANTREA_PROXY |
✔ | ✔ | Optional; defaults to true. Activates or deactivates AntreaProxy, to replace kube-proxy for pod-to-ClusterIP service traffic, for better performance and lower latency. Note that kube-proxy is still used for other types of service traffic. For more information, see Configure Antrea CNI and AntreaProxy in the Antrea documentation. |
ANTREA_PROXY_ALL |
✔ | ✔ | Optional; defaults to false. Activates or deactivates AntreaProxy to handle all types of service traffic (ClusterIP, NodePort, and LoadBalancer) from all nodes and pods. If present, kube-proxy also redundantly handles all service traffic from nodes and hostNetwork pods, including Antrea components, typically before AntreaProxy does. For more information, see Configure Antrea CNI and AntreaProxy in the Antrea documentation. |
ANTREA_PROXY_LOAD_BALANCER_IPS |
✔ | ✔ | Optional; defaults to true. Set to false to direct the load-balance traffic to the external LoadBalancer. |
ANTREA_PROXY_NODEPORT_ADDRS |
✔ | ✔ | Optional. The IPv4 or IPv6 address for NodePort. Include the quotes (““). |
ANTREA_PROXY_SKIP_SERVICES |
✔ | ✔ | Optional. An array of string values that can be used to indicate a list of services that AntreaProxy should ignore. Traffic to these services will not be load-balanced. Include the quotes (””). For example, a valid ClusterIP, such as 10.11.1.2, or a service name with a Namespace, such as kube-system/kube-dns, are valid values. For more information, see Special use cases in the Antrea documentation. |
ANTREA_SERVICE_EXTERNALIP |
✔ | ✔ | Optional; defaults to false. Set to true, with ANTREA_PROXY_ALL also true, to enable a controller to allocate external IPs from an ExternalIPPool resource for services with type LoadBalancer. For more information on how to implement services of type LoadBalancer, see Service of type LoadBalancer in the Antrea documentation. |
ANTREA_TRACEFLOW |
✔ | ✔ | Optional; defaults to true. For information about using Traceflow, see the Traceflow User Guide in the Antrea documentation. |
ANTREA_TRAFFIC_ENCAP_MODE |
✔ | ✔ | Optional; defaults to Note:
|
ANTREA_TRANSPORT_INTERFACE |
✔ | ✔ | Optional. The name of the interface on node that is used for tunneling or routing the traffic. Include the quotes (““). For example, “eth0”. |
ANTREA_TRANSPORT_INTERFACE_CIDRS |
✔ | ✔ | Optional. The network CIDRs of the interface on node that is used for tunneling or routing the traffic. Include the quotes (””). For example, “10.0.0.2/24”. |
Machine Health Checks
If you want to configure machine health checks for management and workload clusters, set the following variables. For more information, see Configure Machine Health Checks in Create a Management Cluster Configuration File. For information about how to perform machine health check operations after cluster deployment, see Configure Machine Health Checks for Workload Clusters.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
ENABLE_MHC |
✔ | class-based: ✖ plan-based: ✔ |
Optional, set to true or false to activate or deactivate the MachineHealthCheck controller on both the control plane and worker nodes of the target management or workload cluster. Or leave empty and set ENABLE_MHC_CONTROL_PLANE and ENABLE_MHC_WORKER_NODE separately for control plane and worker nodes. Default is empty.The controller provides machine health monitoring and auto-repair. |
ENABLE_MHC_CONTROL_PLANE |
✔ | Optional; defaults to true. For more information, see the table below. |
|
ENABLE_MHC_WORKER_NODE |
✔ | Optional; defaults to true. For more information, see the table below. |
|
MHC_MAX_UNHEALTHY_CONTROL_PLANE |
✔ | ✖ | Optional; class-based clusters only. Defaults to 100%. If the number of unhealthy machines exceeds the value you set, the MachineHealthCheck controller does not perform remediation. |
MHC_MAX_UNHEALTHY_WORKER_NODE |
✔ | ✖ | Optional; class-based clusters only. Defaults to 100%. If the number of unhealthy machines exceeds the value you set, the MachineHealthCheck controller does not perform remediation. |
MHC_FALSE_STATUS_TIMEOUT |
✔ | class-based: ✖ plan-based: ✔ |
Optional; defaults to 12m. How long the MachineHealthCheck controller allows a node’s Ready condition to remain False before considering the machine unhealthy and recreating it. |
MHC_UNKNOWN_STATUS_TIMEOUT |
✔ | Optional; defaults to 5m. How long the MachineHealthCheck controller allows a node’s Ready condition to remain Unknown before considering the machine unhealthy and recreating it. |
|
NODE_STARTUP_TIMEOUT |
✔ | Optional; defaults to 20m. How long the MachineHealthCheck controller waits for a node to join a cluster before considering the machine unhealthy and recreating it. |
|
Use the table below to determine how to configure the ENABLE_MHC, ENABLE_MHC_CONTROL_PLANE, and ENABLE_MHC_WORKER_NODE variables.
Value of ENABLE_MHC |
Value of ENABLE_MHC_CONTROL_PLANE |
Value of ENABLE_MHC_WORKER_NODE |
Control plane remediation enabled? | Worker node remediation enabled? |
|---|---|---|---|---|
true / Empty |
true / false / Empty |
true / false / Empty |
Yes | Yes |
false |
true / Empty |
true / Empty |
Yes | Yes |
false |
true / Empty |
false |
Yes | No |
false |
false |
true / Empty |
No | Yes |
Private Image Registry Configuration
If you deploy Tanzu Kubernetes Grid management clusters and Kubernetes clusters in environments that are not connected to the Internet, you need to set up a private image repository within your firewall and populate it with the Tanzu Kubernetes Grid images. For information about setting up a private image repository, see Prepare an Internet-Restricted Environment.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
ADDITIONAL_IMAGE_REGISTRY_1, ADDITIONAL_IMAGE_REGISTRY_2, ADDITIONAL_IMAGE_REGISTRY_3 |
✔ | ✔ | Class-based workload and standalone management clusters only. The IP addresses or FQDNs of up to three trusted private registries, in addition to the primary image registry set by TKG_CUSTOM_IMAGE_REPOSITORY, for workload cluster nodes to access. See Trusted Registries for a Class-Based Cluster. |
ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_2_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_3_CA_CERTIFICATE |
✔ | ✔ | Class-based workload and standalone management clusters only. The CA certificates in base64-encoded format of private image registries configured with ADDITIONAL_IMAGE_REGISTRY- above. For example ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE: “LS0t[…]tLS0tLQ==”.. |
ADDITIONAL_IMAGE_REGISTRY_1_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_2_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_3_SKIP_TLS_VERIFY |
✔ | ✔ | Class-based workload and standalone management clusters only. Set to true for any private image registries configured with ADDITIONAL_IMAGE_REGISTRY- above that use a self-signed certificate but do not use ADDITIONAL_IMAGE_REGISTRY_CA_CERTIFICATE. Because the Tanzu connectivity webhook injects the Harbor CA certificate into cluster nodes, ADDITIONAL_IMAGE_REGISTRY_SKIP_TLS_VERIFY should always be set to false when using Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY |
✔ | ✔ | Required if you deploy Tanzu Kubernetes Grid in an Internet-restricted environment. Provide the IP address or FQDN of the private registry that contains TKG system images that clusters bootstrap from, called the primary image registry below. For example, custom-image-repository.io/yourproject. |
TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY |
✔ | ✔ | Optional. Set to true if your private primary image registry uses a self-signed certificate and you do not use TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE. Because the Tanzu connectivity webhook injects the Harbor CA certificate into cluster nodes, TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY should always be set to false when using Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE |
✔ | ✔ | Optional. Set if your private primary image registry uses a self-signed certificate. Provide the CA certificate in base64 encoded format, for example TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE: “LS0t[…]tLS0tLQ==”. |
vSphere
The options in the table below are the minimum options that you specify in the cluster configuration file when deploying workload clusters to vSphere. Most of these options are the same for both the workload cluster and the management cluster that you use to deploy it.
For more information about the configuration files for vSphere, see Management Cluster Configuration for vSphere and Deploy Workload Clusters to vSphere.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
DEPLOY_TKG_ON_VSPHERE7 |
✔ | ✔ | Optional. If deploying to vSphere 7 or 8, set to true to skip the prompt about deployment on vSphere 7 or 8, or false. |
ENABLE_TKGS_ON_VSPHERE7 |
✔ | ✔ | Optional if deploying to vSphere 7 or 8, set to true to be redirected to the vSphere IaaS control plane enablement UI page, or false. |
NTP_SERVERS |
✔ | ✔ | Class-based clusters only. Configures the cluster’s NTP server if you are deploying clusters in a vSphere environment that lacks DHCP Option 42, for example NTP_SERVERS: time.google.com. To configure this in a legacy, plan-based cluster, use a ytt overlay as described in Configuring NTP without DHCP Option 42 (vSphere). |
TKG_IP_FAMILY |
✔ | ✔ | Optional. To deploy a cluster to vSphere 7 or 8 with pure IPv6, set this to ipv6. For dual-stack networking, see Setting the Primary IP Family. |
VIP_NETWORK_INTERFACE |
✔ | ✔ | Optional. Set to eth0, eth1, etc. Network interface name, for example an Ethernet interface. Defaults to eth0. |
VSPHERE_AZ_CONTROL_PLANE_MATCHING_LABELS |
✔ | ✔ | For clusters deployed to multiple AZs, sets key/value selector labels for specifying AZs that cluster control plane nodes may deploy to. This lets you configure the nodes, for example, to run in all of the AZs in a specified region and environment without listing the AZs individually, for example: “region=us-west-1,environment=staging”. See Running Clusters Across Multiple Availability Zones |
VSPHERE_AZ_0, VSPHERE_AZ_1, VSPHERE_AZ_2 |
✔ | ✔ | Optional The deployment zones to which machine deployments in a cluster get deployed to. See Running Clusters Across Multiple Availability Zones |
VSPHERE_CONTROL_PLANE_DISK_GIB |
✔ | ✔ | Optional. The size in gigabytes of the disk for the control plane node VMs. Include the quotes (““). For example, "30". |
VSPHERE_CONTROL_PLANE_ENDPOINT |
✔ | ✔ | Required for Kube-Vip. Static virtual IP address, or fully qualified domain name (FQDN) mapped to static address, for API requests to the cluster. This setting is required if you are using Kube-Vip for your API server endpoint, as configured by setting AVI_CONTROL_PLANE_HA_PROVIDER to falseIf you use NSX Advanced Load Balancer, AVI_CONTROL_PLANE_HA_PROVIDER: true, you can:
|
VSPHERE_CONTROL_PLANE_ENDPOINT_PORT |
✔ | ✔ | Optional, set if you want to override the Kubernetes API server port for deployments on vSphere with NSX Advanced Load Balancer. The default port is 6443. To override the Kubernetes API server port for deployments on vSphere without NSX Advanced Load Balancer, set CLUSTER_API_SERVER_PORT. |
VSPHERE_CONTROL_PLANE_MEM_MIB |
✔ | ✔ | Optional. The amount of memory in megabytes for the control plane node VMs. Include the quotes (””). For example, "2048". |
VSPHERE_CONTROL_PLANE_NUM_CPUS |
✔ | ✔ | Optional. The number of CPUs for the control plane node VMs. Include the quotes (““). Must be at least 2. For example, "2". |
VSPHERE_DATACENTER |
✔ | ✔ | Required. The name of the datacenter in which to deploy the cluster, as it appears in the vSphere inventory. For example, /MY-DATACENTER. |
VSPHERE_DATASTORE |
✔ | ✔ | Required. The name of the vSphere datastore for the cluster to use, as it appears in the vSphere inventory. For example, /MY-DATACENTER/datastore/MyDatastore. |
VSPHERE_FOLDER |
✔ | ✔ | Required. The name of an existing VM folder in which to place Tanzu Kubernetes Grid VMs, as it appears in the vSphere inventory. For example, if you created a folder named TKG, the path is /MY-DATACENTER/vm/TKG. |
VSPHERE_INSECURE |
✔ | ✔ | Optional. Set to true to bypass thumbprint verification. If false, set VSPHERE_TLS_THUMBPRINT. |
VSPHERE_MTU |
✔ | ✔ | Optional. Set the size of the maximum transmission unit (MTU) for management and workload cluster nodes on a vSphere Standard Switch. Defaults to 1500 if not set. Maximum value is 9000. See Configure Cluster Node MTU. |
VSPHERE_NETWORK |
✔ | ✔ | Required. The name of an existing vSphere network to use as the Kubernetes service network, as it appears in the vSphere inventory. For example, VM Network. |
VSPHERE_PASSWORD |
✔ | ✔ | Required. The password for the vSphere user account. This value is base64-encoded when you run tanzu cluster create. |
VSPHERE_REGION |
✔ | ✔ | Optional. Tag for region in vCenter, used to:
|
VSPHERE_RESOURCE_POOL |
✔ | ✔ | Required. The name of an existing resource pool in which to place this Tanzu Kubernetes Grid instance, as it appears in the vSphere inventory. To use the root resource pool for a cluster, enter the full path, for example for a cluster named cluster0 in datacenter MY-DATACENTER, the full path is /MY-DATACENTER/host/cluster0/Resources. |
VSPHERE_SERVER |
✔ | ✔ | Required. The IP address or FQDN of the vCenter Server instance on which to deploy the workload cluster. |
VSPHERE_SSH_AUTHORIZED_KEY |
✔ | ✔ | Required. Paste in the contents of the SSH public key that you created in Deploy a Management Cluster to vSphere. For example, "ssh-rsa NzaC1yc2EA […] hnng2OYYSl+8ZyNz3fmRGX8uPYqw== email@example.com". |
VSPHERE_STORAGE_POLICY_ID |
✔ | ✔ | Optional. The name of a VM storage policy for the management cluster, as it appears in Policies and Profiles > VM Storage Policies. If VSPHERE_DATASTORE is set, the storage policy must include it. Otherwise, the cluster creation process chooses a datastore that compatible with the policy. |
VSPHERE_TEMPLATE |
✖ | ✔ | Optional. Specify the path to an OVA file if you are using multiple custom OVA images for the same Kubernetes version, in the format /MY-DC/vm/MY-FOLDER-PATH/MY-IMAGE. For more information, see Deploy a Cluster with a Custom OVA Image. |
VSPHERE_TLS_THUMBPRINT |
✔ | ✔ | Required if VSPHERE_INSECURE is false. The thumbprint of the vCenter Server certificate. For information about how to obtain the vCenter Server certificate thumbprint, see Obtain vSphere Certificate Thumbprints. This value can be skipped if user wants to use insecure connection by setting VSPHERE_INSECURE to true. |
VSPHERE_USERNAME |
✔ | ✔ | Required. A vSphere user account, including the domain name, with the required privileges for Tanzu Kubernetes Grid operation. For example, tkg-user@vsphere.local. |
VSPHERE_WORKER_DISK_GIB |
✔ | ✔ | Optional. The size in gigabytes of the disk for the worker node VMs. Include the quotes (””). For example, "50". |
VSPHERE_WORKER_MEM_MIB |
✔ | ✔ | Optional. The amount of memory in megabytes for the worker node VMs. Include the quotes (““). For example, "4096". |
VSPHERE_WORKER_NUM_CPUS |
✔ | ✔ | Optional. The number of CPUs for the worker node VMs. Include the quotes (””). Must be at least 2. For example, "2". |
VSPHERE_ZONE |
✔ | ✔ | Optional. Tag for zone in vCenter, used to:
|
Kube-VIP Load Balancer (Technical Preview)
For information about how to configure Kube-VIP as an L4 load balancer service, see Kube-VIP Load Balancer.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
KUBEVIP_LOADBALANCER_ENABLE |
✖ | ✔ | Optional; defaults to false. Set to true or false. Enables Kube-VIP as a load balancer for workloads. If true, you must set one of the variables below. |
KUBEVIP_LOADBALANCER_IP_RANGES |
✖ | ✔ | A list of non-overlapping IP ranges to allocate for LoadBalancer type service IP. For example: 10.0.0.1-10.0.0.23,10.0.2.1-10.0.2.24. |
KUBEVIP_LOADBALANCER_CIDRS |
✖ | ✔ | A list of non-overlapping CIDRs to allocate for LoadBalancer type service IP. For example: 10.0.0.0/24,10.0.2/24. Overrides the setting for KUBEVIP_LOADBALANCER_IP_RANGES. |
NSX Advanced Load Balancer
For information about how to deploy NSX Advanced Load Balancer, see Install NSX Advanced Load Balancer.
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
AVI_ENABLE |
✔ | ✖ | Optional; defaults to false. Set to true or false. Enables NSX Advanced Load Balancer as a load balancer for workloads. If true, you must set the required variables listed in NSX Advanced Load Balancer below. |
AVI_ADMIN_CREDENTIAL_NAME |
✔ | ✖ | Optional; defaults to avi-controller-credentials. The name of the Kubernetes Secret that contains the NSX Advanced Load Balancer controller admin username and password. |
AVI_AKO_IMAGE_PULL_POLICY |
✔ | ✖ | Optional; defaults to IfNotPresent. |
AVI_CA_DATA_B64 |
✔ | ✖ | Required. The contents of the Controller Certificate Authority that is used to sign the Controller certificate. It must be base64 encoded. Retrieve unencoded custom certificate contents as described in Avi Controller Setup: Custom Certificate. |
AVI_CA_NAME |
✔ | ✖ | Optional; defaults toavi-controller-ca. The name of the Kubernetes Secret that holds the NSX Advanced Load Balancer Controller Certificate Authority. |
AVI_CLOUD_NAME |
✔ | ✖ | Required. The cloud that you created in your NSX Advanced Load Balancer deployment. For example, Default-Cloud. |
AVI_CONTROLLER |
✔ | ✖ | Required. The IP or hostname of the NSX Advanced Load Balancer controller. |
AVI_CONTROL_PLANE_HA_PROVIDER |
✔ | ✔ | Required. Set to true to enable NSX Advanced Load Balancer as the control plane API server endpoint, or false to use Kube-Vip as the control plane endpoint. |
AVI_CONTROL_PLANE_NETWORK |
✔ | ✖ | Optional. Defines the VIP network of the workload cluster’s control plane. Use when you want to configure a separate VIP network for the workload clusters. This field is optional, and if it is left empty, it will use the same network as AVI_DATA_NETWORK. |
AVI_CONTROL_PLANE_NETWORK_CIDR |
✔ | ✖ | Optional; defaults to the same network as AVI_DATA_NETWORK_CIDR. The CIDR of the subnet to use for the workload cluster’s control plane. Use when you want to configure a separate VIP network for the workload clusters. You can see the subnet CIDR for a particular network in the Infrastructure - Networks view of the NSX Advanced Load Balancer interface. |
AVI_DATA_NETWORK |
✔ | ✖ | Required. The network’s name on which the floating IP subnet or IP Pool is assigned to a load balancer for traffic to applications hosted on workload clusters. This network must be present in the same vCenter Server instance as the Kubernetes network that Tanzu Kubernetes Grid uses, that you specify in the SERVICE_CIDR variable. This allows NSX Advanced Load Balancer to discover the Kubernetes network in vCenter Server and to deploy and configure service engines. |
AVI_DATA_NETWORK_CIDR |
✔ | ✖ | Required. The CIDR of the subnet to use for the load balancer VIP. This comes from one of the VIP network’s configured subnets. You can see the subnet CIDR for a particular network in the Infrastructure - Networks view of the NSX Advanced Load Balancer interface. |
AVI_DISABLE_INGRESS_CLASS |
✔ | ✖ | Optional; defaults to false. Deactivate Ingress Class.. |
AVI_DISABLE_STATIC_ROUTE_SYNC |
✔ | ✖ | Optional; defaults to false. Set to true if the pod networks are reachable from the NSX ALB service engine. |
AVI_INGRESS_DEFAULT_INGRESS_CONTROLLER |
✔ | ✖ | Optional; defaults to false. Use AKO as the default Ingress Controller.Note: This variable does not work in TKG v2.3. For a workaround, see Known Issue Some NSX ALB Configuration Variables Do Not Work in the release notes. |
AVI_INGRESS_NODE_NETWORK_LIST |
✔ | ✖ | Specifies the name of the port group (PG) network that your nodes are a part of and the associated CIDR that the CNI allocates to each node for that node to assign to its pods. It is best to update this in the AKODeploymentConfig file, see L7 Ingress in ClusterIP Mode, but if you do use the cluster configuration file, the format is similar to: ‘[{“networkName”: “vsphere-portgroup”,“cidrs”: [“100.64.42.0/24”]}]’ |
AVI_INGRESS_SERVICE_TYPE |
✔ | ✖ | Optional. Specifies whether the AKO functions in ClusterIP, NodePort, or NodePortLocal mode. Defaults to NodePort. NSX ALB NodePortLocal ingress mode is not supported for management clusters. You cannot run NSX ALB as a service type with ingress mode NodePortLocal for traffic to the management cluster. |
AVI_INGRESS_SHARD_VS_SIZE |
✔ | ✖ | Optional. AKO uses a sharding logic for Layer 7 ingress objects. A sharded VS involves hosting multiple insecure or secure ingresses hosted by one virtual IP or VIP. Set to LARGE, MEDIUM, or SMALL. Default SMALL. Use this to control the layer 7 VS numbers. This applies to both secure/insecure VSes but does not apply for passthrough. |
AVI_LABELS |
✔ | ✔ | Optional. When set, NSX Advanced Load Balancer is enabled only on workload clusters that have this label. Include the quotes (""). For example, AVI_LABELS: “{foo: ‘bar’}”. |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_CIDR |
✔ | ✖ | Optional. The CIDR of the subnet to use for the management cluster’s control plane. Use when you want to configure a separate VIP network for the management cluster’s control plane. You can see the subnet CIDR for a particular network in the Infrastructure - Networks view of the NSX Advanced Load Balancer interface. This field is optional, and if it is left empty, it will use the same network as AVI_DATA_NETWORK_CIDR. |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_NAME |
✔ | ✖ | Optional. Defines the VIP network of the management cluster’s control plane. Use when you want to configure a separate VIP network for the management cluster’s control plane. This field is optional, and if it is left empty, it will use the same network as AVI_DATA_NETWORK. |
AVI_MANAGEMENT_CLUSTER_SERVICE_ENGINE_GROUP |
✔ | ✖ | Optional. Specifies the name of the Service Engine group that is to be used by AKO in the management cluster. This field is optional, and if it is left empty, it will use the same network as AVI_SERVICE_ENGINE_GROUP. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_NAME |
✔ | ✖ | Optional; defaults to the same network as AVI_DATA_NETWORK. The network’s name where you assign a floating IP subnet or IP pool to a load balancer for management cluster and workload cluster control plane (if using NSX ALB to provide control plane HA). This network must be present in the same vCenter Server instance as the Kubernetes network that Tanzu Kubernetes Grid uses, which you specify in the SERVICE_CIDR variable for the management cluster. This allows NSX Advanced Load Balancer to discover the Kubernetes network in vCenter Server and to deploy and configure service engines. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_CIDR |
✔ | ✖ | Optional; defaults to the same network as AVI_DATA_NETWORK_CIDR. The CIDR of the subnet to use for the management cluster and workload cluster’s control plane (if using NSX ALB to provide control plane HA) load balancer VIP. This comes from one of the VIP network’s configured subnets. You can see the subnet CIDR for a particular network in the Infrastructure - Networks view of the NSX Advanced Load Balancer interface. |
AVI_NAMESPACE |
✔ | ✖ | Optional; defaults to “tkg-system-networking”. The namespace for AKO operator. |
AVI_NSXT_T1LR |
✔ | ✖ | Optional. The NSX T1 router path that you configured for your management cluster in the Avi Controller UI, under NSX Cloud. This is required when you use NSX cloud on your NSX ALB controller.To use a different T1 for your workload clusters, modify the AKODeploymentConfig object install-ako-for-all after the management cluster is created. |
AVI_PASSWORD |
✔ | ✖ | Required. The password that you set for the Controller admin when you deployed it. |
AVI_SERVICE_ENGINE_GROUP |
✔ | ✖ | Required. Name of the Service Engine Group. For example, Default-Group. |
AVI_USERNAME |
✔ | ✖ | Required. The admin username that you set for the Controller host when you deployed it. |
NSX Pod Routing
These variables configure routable-IP address workload pods, as described in Deploy a Cluster with Routable-IP Pods. All string type settings should be in double-quotes, for example "true".
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
NSXT_POD_ROUTING_ENABLED |
✖ | ✔ | Optional; defaults to “false”. Set to “true” to enable NSX routable pods with the variables below. See Deploy a Cluster with Routable-IP Pods. |
NSXT_MANAGER_HOST |
✖ | ✔ | Required if NSXT_POD_ROUTING_ENABLED= “true”.IP address of NSX Manager. |
NSXT_ROUTER_PATH |
✖ | ✔ | Required if NSXT_POD_ROUTING_ENABLED= “true”. T1 router path shown in NSX Manager. |
| For username/password authentication to NSX: | |||
NSXT_USERNAME |
✖ | ✔ | Username for logging in to NSX Manager. |
NSXT_PASSWORD |
✖ | ✔ | Password for logging in to NSX Manager. |
For authenticating to NSX using credentials and storing them in a Kubernetes secret (also set NSXT_USERNAME and NSXT_PASSWORD above): |
|||
NSXT_SECRET_NAMESPACE |
✖ | ✔ | Optional; defaults to “kube-system”. The namespace with the secret containing NSX username and password. |
NSXT_SECRET_NAME |
✖ | ✔ | Optional; defaults to “cloud-provider-vsphere-nsxt-credentials”. The name of the secret containing NSX username and password. |
| For certificate authentication to NSX: | |||
NSXT_ALLOW_UNVERIFIED_SSL |
✖ | ✔ | Optional; defaults to false. Set this to “true” if NSX uses a self-signed certificate. |
NSXT_ROOT_CA_DATA_B64 |
✖ | ✔ | Required if NSXT_ALLOW_UNVERIFIED_SSL= “false”.Base64-encoded Certificate Authority root certificate string that NSX uses for LDAP authentication. |
NSXT_CLIENT_CERT_KEY_DATA |
✖ | ✔ | Base64-encoded cert key file string for local client certificate. |
NSXT_CLIENT_CERT_DATA |
✖ | ✔ | Base64-encoded cert file string for local client certificate. |
| For remote authentication to NSX with VMware Identity Manager, on VMware Cloud (VMC): | |||
NSXT_REMOTE_AUTH |
✖ | ✔ | Optional; defaults to false. Set this to “true” for remote authentication to NSX with VMware Identity Manager, on VMware Cloud (VMC). |
NSXT_VMC_AUTH_HOST |
✖ | ✔ | Optional; default is empty. VMC authentication host. |
NSXT_VMC_ACCESS_TOKEN |
✖ | ✔ | Optional; default is empty. VMC authentication access token. |
Node IPAM
These variables configure in-cluster IP Address Management (IPAM) as described in Node IPAM. All string type settings should be in double-quotes, for example "true".
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | Comma-delimited list of nameservers, for example, “10.10.10.10”, for control plane node addresses managed by Node IPAM. Supported on Ubuntu and Photon; not supported on Windows. |
NODE_IPAM_IP_POOL_APIVERSION |
✖ | ✔ | API version for InClusterIPPool object used by workload cluster. Defaults to “ipam.cluster.x-k8s.io/v1alpha2”; prior TKG versions used v1alpha1. |
NODE_IPAM_IP_POOL_KIND |
✖ | ✔ | Type of IP pool object used by workload cluster. Defaults to “InClusterIPPool” or can be “GlobalInClusterIPPool” to share same pool with other clusters. |
NODE_IPAM_IP_POOL_NAME |
✖ | ✔ | Name of IP pool object that configures IP pool used by a workload cluster. |
NODE_IPAM_SECONDARY_IP_POOL_APIVERSION, NODE_IPAM_SECONDARY_IP_POOL_KIND, NODE_IPAM_SECONDARY_IP_POOL_NAME |
✖ | ✔ | For dual-stack networking, sets values that correspond to NODE_IPAM_IP_POOL_APIVERSION, NODE_IPAM_IP_POOL_KIND, and NODE_IPAM_IP_POOL_NAME but for the secondary IP pool, as described in IPv4/IPv6 Dual-Stack Networking |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | Comma-delimited list of nameservers, for example, “10.10.10.10”, for worker node addresses managed by Node IPAM. Supported on Ubuntu and Photon; not supported on Windows. |
MANAGEMENT_NODE_IPAM_IP_POOL_GATEWAY |
✔ | ✖ | The default gateway for IPAM pool addresses in a management cluster, for example "10.10.10.1". |
MANAGEMENT_NODE_IPAM_IP_POOL_ADDRESSES |
✔ | ✖ | The addresses available for IPAM to allocate in a management cluster, in a comma-delimited list that can include single IP addresses, ranges (e.g 10.0.0.2-10.0.0.100), or CIDRs (e.g. 10.0.0.32/27).Include extra addresses to remain unused, as needed for cluster upgrades. The required number of extra addresses defaults to one and is set by the annotation topology.cluster.x-k8s.io/upgrade-concurrency in the cluster object spec’s topology.controlPlane and topology.workers definitions. |
MANAGEMENT_NODE_IPAM_SECONDARY_IP_POOL_APIVERSION, MANAGEMENT_NODE_IPAM_SECONDARY_IP_POOL_KIND, MANAGEMENT_NODE_IPAM_SECONDARY_IP_POOL_NAME |
✔ | ✖ | For dual-stack networking, sets values that correspond to MANAGEMENT_NODE_IPAM_IP_POOL_APIVERSION, MANAGEMENT_NODE_IPAM_IP_POOL_KIND, and MANAGEMENT_NODE_IPAM_IP_POOL_NAME but for the secondary IP pool, as described in IPv4/IPv6 Dual-Stack Networking |
MANAGEMENT_NODE_IPAM_IP_POOL_SUBNET_PREFIX |
✔ | ✖ | The network prefix of the subnet for IPAM pool addresses in a standalone management cluster, for example “24” |
GPU-Enabled Clusters
These variables configure GPU-enabled workload clusters in PCI passthrough mode, as described in Deploy a GPU-Enabled Workload Cluster. All string type settings should be in double-quotes, for example "true".
| Variable | Can be set in… | Description | |
|---|---|---|---|
| Management cluster YAML | Workload cluster YAML | ||
VSPHERE_CONTROL_PLANE_CUSTOM_VMX_KEYS |
✔ | ✔ | Sets custom VMX keys on all control plane machines. Use the form Key1=Value1,Key2=Value2. See Deploy a GPU-Enabled Workload Cluster. |
VSPHERE_CONTROL_PLANE_HARDWARE_VERSION |
✔ | ✔ | The hardware version for the control plane VM with the GPU device in PCI passthrough mode. The minimum version required is 17. The format of the value is vmx-17, where the trailing digits are the hardware version of the virtual machine. For feature support on different hardware versions, see Hardware Features Available with Virtual Machine Compatibility Settings in the vSphere documentation. |
VSPHERE_CONTROL_PLANE_PCI_DEVICES |
✔ | ✔ | Configures PCI passthrough on all control plane machines. Use the format <vendor_id>:<device_id>. For example, VSPHERE_WORKER_PCI_DEVICES: “0x10DE:0x1EB8”. To find the vendor and device IDs, see Deploy a GPU-Enabled Workload Cluster. |
VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST |
✔ | ✔ | Set to false if you are using the NVIDIA Tesla T4 GPU and true if you are using the NVIDIA V100 GPU. |
VSPHERE_WORKER_CUSTOM_VMX_KEYS |
✔ | ✔ | Sets custom VMX keys on all worker machines. Use the form Key1=Value1,Key2=Value2. For an example, see Deploy a GPU-Enabled Workload Cluster. |
VSPHERE_WORKER_HARDWARE_VERSION |
✔ | ✔ | The hardware version for the worker VM with the GPU device in PCI passthrough mode. The minimum version required is 17. The format of the value is vmx-17, where the trailing digits are the hardware version of the virtual machine. For feature support on different hardware versions, see Hardware Features Available with Virtual Machine Compatibility Settings in the vSphere documentation. |
VSPHERE_WORKER_PCI_DEVICES |
✔ | ✔ | Configures PCI passthrough on all worker machines. Use the format <vendor_id>:<device_id>. For example, VSPHERE_WORKER_PCI_DEVICES: “0x10DE:0x1EB8”. To find the vendor and device IDs, see Deploy a GPU-Enabled Workload Cluster. |
WORKER_ROLLOUT_STRATEGY |
✔ | ✔ | Optional. Configures the MachineDeployment rollout strategy. Default is RollingUpdate. If set to OnDelete, then on updates, the existing worker machines will be deleted first, before the replacement worker machines are created. It is imperative to set this to OnDelete if all the available PCI devices are in use by the worker nodes. |
Configuration Value Precedence
When the Tanzu CLI creates a cluster, it reads in values for the variables listed in this topic from multiple sources. If those sources conflict, it resolves conflicts in the following order of descending precedence:
| Processing layers, ordered by descending precedence | Source | Examples |
|---|---|---|
| 1. Management cluster configuration variables set in the installer interface | Entered in the installer interface launched by the –ui option, and written to cluster configuration files. File location defaults to ~/.config/tanzu/tkg/clusterconfigs/. |
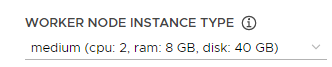 |
| 2. Cluster configuration variables set in your local environment | Set in shell. | export CLUSTER_PLAN=prod |
3. Cluster configuration variables set in the Tanzu CLI, with tanzu config set env. |
Set in shell; saved in the global Tanzu CLI configuration file, ~/.config/tanzu/config.yaml. |
tanzu config set env.CLUSTER_PLAN prod |
| 4. Cluster configuration variables set in the cluster configuration file | Set in the file passed to the –file option of tanzu management-cluster create or tanzu cluster create. File defaults to ~/.config/tanzu/tkg/cluster-config.yaml. |
CLUSTER_PLAN: prod |
| 5. Factory default configuration values | Set in providers/config_default.yaml. Do not modify this file. |
CLUSTER_PLAN: dev |
